 |
|
This page discusses certain issues of terminology in the nnet3 setup about chunk sizes for decoding and training, and left and right context. This will be helpful in understanding some of the scripts. At the current time don't have any 'overview' documentation of nnet3 from a scripting perspective, so this will have to stand as an isolated piece of documentation.
If you have read the previous documentation available for The "nnet3" setup, you will realize that the "nnet3" setup supports setups other than simple feedforward DNNs. It can be used for time delay neural networks (TDNNs) where temporal splicing (frame splicing) is done at internal layers of the network; and also for recurrent topologies (RNNs, LSTMs, BLSTMs, etc.). So nnet3 "knows about" the time axis. Below we estabilish some terminology.
Suppose we want a network to compute an output for a specific time index; to be concrete, say time t = 154. If the network does frame splicing internally (or anything else nontrivial with the 't' indexes), it may not be able to compute this output without seeing a range of input frames. For example, it may be impossible to compute the output without seeing the range of 't' values from t = 150 through t = 157. In this case (glossing over details), we'd say that the network has a left-context of 4 and a right-context of 3. The actual computation of the context is a bit more complex as it has to take into account special cases like where, say, the behavior for odd and even 't' values is different (c.f. Round() descriptors in Descriptors in config files).
There are cases with recurrent topologies where, in addition to the "required" left and right context, we want to give the training or the decoding "extra" context. For such topologies, the network can make use of context beyond the required context. In the scripts you'll generally see variables called extra-left-context and extra-right-context, which mean "the amount of context that we're going to provide in addition to what is required".
In some circumstances the names left-context and right-context simply mean the total left and right context that we're adding to the chunks, i.e. the sums of the model left/right context and the extra left/right context. So in some circumstances you may have to work out from the context whether a variable refers to the model left/right context of the left/right context of the chunks of data.
In Kaldi version 5.0 and earlier the left and right context in the chunks of data is not affected by whether the chunks were at the beginning or end of the utterance; at the ends we pad the input with copies of the first or last frame. This means that for recurrent topologies, we might end up padding the start or end of the utterance with a lot of frames (up to 40 or so). This is wasteful and rather strange. In versions 5.1 and later, you can specify configuration values extra-left-context-initial and extra-right-context-final that allow the start/end of the utterance to have a different amount of context. If you specify these values, you would normally specify them both to be 0 (i.e. no extra context). However, for back compatibility to older setups, they generally default to -1 (meaning, just copy the default extra-left-context and extra-right-context).
The chunk-size is the number of (output) frames for each chunk of data that we evaluate in training or decoding. In the get_egs.sh script and train_dnn.py it is also referred to as frames-per-eg (in some contexts, this is not the same as the chunk size; see below). In decoding we call this the frames-per-chunk.
For the very simplest types of networks, such as feedforward networks or TDNNs trained with the cross-entropy objective function, we randomize the entire dataset at the frame level and we just train on one frame at a time. In order for the training jobs to mostly do sequential I/O, we aim pre-randomize the data at the frame level. However, when you consider that we might easily require 10 frames each of left and right context, and we have to write this out, we could easily be increasing the amount of data by a factor of 20 or so when we generate the training examples. To solve this problem we include labels for a range of time values, controlled by frames-per-eg (normally 8), and include enough left/right context that we can train on any of those 8 frames. Then when we train the model, any given training job will pick one of those 8 frames to train on.
In models that are RNNs or LSTMs or are 'Chain' models, we always train on fairly large chunks (generally in the range 40 to 150 frames). This is referred to as the chunk-size. When we decode, we also generally evaluate the neural net on fairly large chunks of data (like, 30, 50 or 100 frames). This is usually referred to as the frames-per-chunk. For recurrent networks we tend to make sure that the chunk-size/frames-per-chunk and the extra-left-context and extra-right-context are about the same in training and decoding, because this generally gives the best results (although sometimes it's best to make the extra-context values slightly larger in decoding). One might expect that in decoding time longer context would always be better, but this does not always seem to be the case (however, see Looped decoding below, where we mention a way around this).
In cases where there is frame-subsampling at the output (like the chain model), the chunk-size is still measured in multiples of 't', and we make sure (via rounding up in the code) that it's a multiple of the frame-subsampling factor. Bear in mind that if the chunk-size is 90 and the frame-subsampling-factor is 3, then we're only evaluating 30 distinct output indexes for each chunk of 90 frames (e.g. t=0, t=3 ... t=87).
Variable chunk size is something used in training that is only available in Kaldi version 5.1 or later. This is a mechanism to allow fairly large chunks while avoiding the loss of data due to files that are not exact multiples of the chunk size. Instead of specifying the chunk size as (say) 150, we might specify the chunk size as a comma-separated list like 150,120,90,75, and the commands that generate the training examples are allowed to create chunks of any of those sizes. The first chunk size specified is referred to as the primary chunk size, and is "special" in that for any given utterance, we are allowed pick at most two of the non-primary chunk size; the remaining chunks must be of the primary chunk size. This restriction makes it easier to work out the optimal split of a file of a given length into chunks, and allows us to bias the chunk-generation to chunks of a certain length.
The program nnet3-merge-egs merges individual training examples into minibatches containing many different examples (each original example gets a different 'n' index). The minibatch-size is the desired size of minibatch, by which we mean the number of examples (frames or sequences) that we combine into one(for example, minibatch-size=128). When the chunk sizes are variable (and taking into account that the context may be different at the start/end of utterances if we set the extra-left-context-initial and extra-right-context-final), it's important to ensure that only ``similar'' examples are merged into minibatches; this prevents expensive recompilation from happening on every single minibatch.
In Kaldi version 5.1 and later, nnet3-merge-egs only merges together chunks of the same structure (i.e. the same chunk-size and left and right context). It keeps reading chunks from the input until it finds that for some structure of input, there are minibatch-size examples ready to merge into one. In Kaldi versions prior to 5.1 we generally discarded the "odd-numbered" examples that couldn't be fit into a normal-sized minibatch, but this becomes problematic now that there are many different chunk-sizes (we'd discard too much data).
From Kaldi 5.1 and later, the –minibatch-size is a more general string that allows the user more control than just having a fixed minibatch size. For example, you can specify –minibatch-size=64,128 and for each type of example it will try to accumulate batches of the largest specified size (128) and output them, until it reaches the end of the input; then it will output a minibatch of size 64 if there are >= 64 egs left. Ranges are also supported, e.g. –minibatch-size=1:64 means to output minibatches of size 64 until the end of the input, then output all remaining examples as a single minibatch. You may also specify different rules for examples of different sizes (run nnet3-merge-egs without arguments for details of this); this can be useful to stay within GPU memory limits.
Looped decoding in nnet3 is another feature that is new in Kaldi version 5.1. It is applicable to forward-recurrent neural networks such as RNNs and LSTMs (but not to BLSTMs). It allows us to re-use hidden-state activations from previously-computed chunks. This allows us to have effectively unlimited left context. The reason why it's called ``looped decoding'' relates to the way it's implemented: we create a computation whose last statement is a 'goto' that jumps to somewhere in the middle, so effectively it has a loop like 'while(1)'. (Note: the computations have statements that request user input or provide output, so the loop doesn't cause the computation to run indefinitely when called; it will stop when an I/O operation is reached). Looped computation is intended to solve two problems: wasteful computation, and latency. Suppose we trained our LSTMs with 40 frames of left context and a chunk-size of 100. Without looped computation, we'd probably want to decode with chunks of size about 100 and we'd left-pad the input with around 40 frames. But this takes about 40% extra computation; and the chunk size of 1 second would be a problem for latency/responsiveness in a real-time application. With looped computation, we can choose any chunk size that's convenient, because the effective left context is infinite; and the chunk size doesn't affect the computed output any more.
However, there is a slight problem with what we sketched out above. In practice, we've found for LSTMs that decoding works best with about the same chunk sizes and context as we trained with. That is, adding more context than we trained on is not helpful. Our theory about why this happens is that as the context gets longer we reach parts of activation space that were unreachable before. The maximum value of the cells 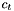 in LSTMs rises linearly with the number of frames we've seen. Following this theory, we made a modification to LSTMs that seems to fix the problem. We scale the in the LSTM equations by a value slightly less than one in the recurrence (for example, like 0.9). This puts a bound on the maximum hidden activation activations and makes them increase less dramatically with increasing recurrence time. It's specified as a configuration value in the LSTM components in the "xconfig" configuration files with the "decay-time" value, e.g. "decay-time=20". This doesn't seem to degrade the Word Error Rates, and it removes the discrepancy between regular and looped decoding (i.e. it makes the networks tolerant to longer context than was seen in training).
in LSTMs rises linearly with the number of frames we've seen. Following this theory, we made a modification to LSTMs that seems to fix the problem. We scale the in the LSTM equations by a value slightly less than one in the recurrence (for example, like 0.9). This puts a bound on the maximum hidden activation activations and makes them increase less dramatically with increasing recurrence time. It's specified as a configuration value in the LSTM components in the "xconfig" configuration files with the "decay-time" value, e.g. "decay-time=20". This doesn't seem to degrade the Word Error Rates, and it removes the discrepancy between regular and looped decoding (i.e. it makes the networks tolerant to longer context than was seen in training).
The script steps/nnet3/decode_looped.sh (only available from Kaldi version 5.1) takes only two chunk- or context-related configuration values: frames-per-chunk (which only affects the speed/latency tradeoff and not results), and extra-left-context-initial, which should be set to match the training condition (generally this will be zero, in up-to-date scripts).
At the time of writing, we have not yet created a program similar to online2-wav-nnet3-latgen-faster that uses the looped decoder; that is on our TODO list (it's not inherently difficult).
 1.8.13
1.8.13