 |
|
This page describes the keyword search module in Kaldi. Our implementation includes the following features:
In the following document, we will focus on word level keyword search for simplicity purpose, but our implementation naturally supports word level as well as subword level keyword search – both our LVCSR module and the KWS module are implemented using weighted finite state transducer (WFST), and the algorithm should work as long as the symbol table properly maps words/subwords to integers.
The rest of this document is organized as follows: in section Typical Kaldi KWS system, we describe the basic components of a Kaldi KWS system; in section Proxy keywords, we explain how we use proxy keywords to handle the keywords that are not in the vocabulary; finally in section Babel scripts, we walk through the KWS related scripts we created for IARPA Babel project.
An example of a Kaldi KWS system can be found in this paper "Quantifying the Value of Pronunciation Lexicons for Keyword Search in Low Resource Languages", G. Chen, S. Khudanpur, D. Povey, J. Trmal, D. Yarowsky and O. Yilmaz. Generally, a KWS system consists of two parts: a LVCSR module that decodes the search collection and generates corresponding lattices, and a KWS module that makes index for the lattices and searches the keywords from the generated index.
Our basic LVCSR system is a SGMM + MMI system. We use standard PLP analysis to extract 13 dimensional acoustic features, and follow a typical maximum likelihood acoustic training recipe, beginning with a flat-start initialization of context-independent phonetic HMMs, and ending with speaker adaptive training (SAT) of state-clustered triphone HMMs with GMM output densities. This is followed by the training of a universal background model from speaker-transformed training data, which is then used to train a subspace Gaussian mixture model (SGMM) for the HMM emission probabilities. Finally, all the training speech is decoded using the SGMM system, and boosted maximum mutual information (BMMI) training of the SGMM parameters is performed. More details can be found in egs/babel/s5b/run-1-main.sh.
We also build additional systems besides the basic SGMM + MMI system. For example, a hybrid deep neural network (DNN) system, details in egs/babel/s5b/run-2a-nnet-gpu.sh, a bottleneck feature system, details in egs/babel/s5b/run-8a-kaldi-bnf.sh, etc. All those systems decode and generate lattices for the same search collection, which will then be sent to the KWS module for indexing and searching. We do system combination on the retrieved results instend of lattices.
Lattices generated by the above LVCSR systems are processed using the lattice indexing technique described in "Lattice indexing for spoken term detection", D. Can, M. Saraclar, Audio, Speech, and Language Processing. The lattices of all the utterances in the search collection are converted from individual weighted finite state transducers (WFST) to a single generalized factor transducer structure in which the start-time, end-time and lattice posterior probability of each word token is stored as a 3-dimensional cost. This factor transducer is actually an inverted index of all word sequences seen in the lattices. Given a keyword or phrase, we then create a simple finite state machine that accepts the keyword/phrase and composes it with the factor transducer to obtain all occurrences of the keyword/phrase in the search collection, along with the utterance ID, start-time and end-time and lattice posterior probability of each occurrence. All those occurrences are sorted according to their posterior probabilities and a YES/NO decision is assigned to each instance using the method proposed in the paper "Rapid and Accurate Spoken Term Detection".
Our proxy keyword generation process has been described in this paper "Using Proxies for OOV Keywords in the Keyword Search Task", G. Chen, O. Yilmaz, J. Trmal, D. Povey, S. Khudanpur. We originally proposed this method to solve the OOV problem of the word lattices – if a keyword is not in the vocabulary of the LVCSR system, it will not appear in the search collection lattices, even though the keyword is actually spoken in the search collection. This is a known problem of LVCSR based keyword search systems, and there are ways to handle this, for example, building a subword system. Our approach is to find acoustically similar in-vocabulary (IV) words for the OOV keyword, and use them as proxy keywords instead of the original OOV keyword. The advantage is that we do not have to build additional subword systems. In a upcoming Interspeech paper "Low-Resource Open Vocabulary Keyword Search Using Point Process Models", C. Liu, A. Jansen, G. Chen, K. Kintzley, J. Trmal, S. Khudanpur, we show that this technique is comparable and complementary to a phonetic search method based on point process model. Proxy keyword is one of the fuzzy search methods, and it should also improve IV keyword performance, although we initially brought it up to handle OOV keywords.
The general proxy keyword generation process can be formulized as follows:
![\[ K^\prime = \mathrm{Project} \left( \mathrm{ShortestPath} \left( \mathrm{Prune} \left( \mathrm{Prune} \left(K \circ L_2 \circ E^\prime \right) \circ L_1^{-1} \right) \right) \right) \]](form_14.png)
where 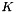 is the original keyword,
is the original keyword, 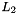 is a lexicon that contains the pronunciation of . If is out of vocabulary, this lexicon can be obtained by using G2P tools such as Sequitur.
is a lexicon that contains the pronunciation of . If is out of vocabulary, this lexicon can be obtained by using G2P tools such as Sequitur. 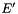 is the edit distance transducer that contains the phone confusions collectioned from training set, and
is the edit distance transducer that contains the phone confusions collectioned from training set, and 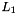 is the original lexicon.
is the original lexicon. 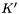 is then a WFST that contains several IV words that are acoustically similar to the original keyword . We plug it into the search pipeline "as if" it was the original keyword.
is then a WFST that contains several IV words that are acoustically similar to the original keyword . We plug it into the search pipeline "as if" it was the original keyword.
Note that the two pruning stages are essential, especially when you have a very large vocabulary. We also implemented a lazy-composition algorithm that only generates composed states as needed (i.e., does not generate states that will be pruned away later). This avoids blowing up the memory when composing 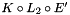 with
with 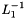 .
.
We have set up the "push-button" scripts for IARPA Babel project. If you are working on Babel and want to use our scripts, you can build a SGMM + MMI keyword search system in the following steps (assume you are in working directory egs/babel/s5b/):
Similarly, you can build DNN systems, BNF systems, Semi-supervised systems, etc. The KWS stuff happens in run-4-anydecode.sh. We will have a detailed look of how to do keyword search below, in case you want to do keyword search for some other resources. We assume that you have decoded your search collection and generated the corresponding lattices.
Typically, we generate KWS data directories under the search collection data directory. For example, if you have a search collection called dev10h.uem, you will have a data directory for it called data/dev10h.uem/. We create KWS data directories under this directory, e.g., data/dev10h.uem/kws/. Before creating KWS data directories, you have to get three files ready by hand: a ecf file that contains the search collection information, a kwlist file that lists all the keywords and a rttm file for scoring. Sometimes you may have to prepare those files by yourself, for example, you can generate the rttm file by force aligning the search collection with a trained model. Below we show the format of those files.
Example ECF file:
<ecf source_signal_duration="483.825" language="" version="Excluded noscore regions"> <excerpt audio_filename="YOUR_AUDIO_FILENAME" channel="1" tbeg="0.000" dur="483.825" source_type="splitcts"/> </ecf>
Example KWLIST file:
<kwlist ecf_filename="ecf.xml" language="tamil" encoding="UTF-8" compareNormalize="" version="Example keywords">
<kw kwid="KW204-00001">
<kwtext>செய்றத</kwtext>
</kw>
<kw kwid="KW204-00002">
<kwtext>சொல்லுவியா</kwtext>
</kw>
</kwlist>
Example RTTM file:
SPEAKER YOUR_AUDIO_FILENAME 1 5.87 0.370 <NA> <NA> spkr1 <NA> LEXEME YOUR_AUDIO_FILENAME 1 5.87 0.370 ஹலோ lex spkr1 0.5 SPEAKER YOUR_AUDIO_FILENAME 1 8.78 2.380 <NA> <NA> spkr1 <NA> LEXEME YOUR_AUDIO_FILENAME 1 8.78 0.300 உம்ம் lex spkr1 0.5 LEXEME YOUR_AUDIO_FILENAME 1 9.08 0.480 அதான் lex spkr1 0.5 LEXEME YOUR_AUDIO_FILENAME 1 9.56 0.510 சரியான lex spkr1 0.5 LEXEME YOUR_AUDIO_FILENAME 1 10.07 0.560 மெசேஜ்டா lex spkr1 0.5 LEXEME YOUR_AUDIO_FILENAME 1 10.63 0.350 சான்ஸே lex spkr1 0.5 LEXEME YOUR_AUDIO_FILENAME 1 10.98 0.180 இல்லயே lex spkr1 0.5
With the above three files ready, you can start preparing KWS data directory. If you just want to do a basic keyword search, running the following should be enough:
local/kws_setup.sh \ --case_insensitive $case_insensitive \ --rttm-file $my_rttm_file \ $my_ecf_file $my_kwlist_file data/lang $dataset_dir
If you want to do fuzzy search for your OOV keywords, you can run the following few commands, which first collects the phone confusions, and trains a G2P model, and then creates the KWS data directory:
#Generate the confusion matrix
#NB, this has to be done only once, as it is training corpora dependent,
#instead of search collection dependent
if [ ! -f exp/conf_matrix/.done ] ; then
local/generate_confusion_matrix.sh --cmd "$decode_cmd" --nj $my_nj \
exp/sgmm5/graph exp/sgmm5 exp/sgmm5_ali exp/sgmm5_denlats exp/conf_matrix
touch exp/conf_matrix/.done
fi
confusion=exp/conf_matrix/confusions.txt
if [ ! -f exp/g2p/.done ] ; then
local/train_g2p.sh data/local exp/g2p
touch exp/g2p/.done
fi
local/apply_g2p.sh --nj $my_nj --cmd "$decode_cmd" \
--var-counts $g2p_nbest --var-mass $g2p_mass \
$kwsdatadir/oov.txt exp/g2p $kwsdatadir/g2p
L2_lex=$kwsdatadir/g2p/lexicon.lex
L1_lex=data/local/lexiconp.txt
local/kws_data_prep_proxy.sh \
--cmd "$decode_cmd" --nj $my_nj \
--case-insensitive true \
--confusion-matrix $confusion \
--phone-cutoff $phone_cutoff \
--pron-probs true --beam $beam --nbest $nbest \
--phone-beam $phone_beam --phone-nbest $phone_nbest \
data/lang $data_dir $L1_lex $L2_lex $kwsdatadir
At this stage we assume you have decoded your search collection and generated the corresponding lattices. Running the following script will take care of indexing and searching:
local/kws_search.sh --cmd "$cmd" \
--max-states ${max_states} --min-lmwt ${min_lmwt} \
--max-lmwt ${max_lmwt} --skip-scoring $skip_scoring \
--indices-dir $decode_dir/kws_indices $lang_dir $data_dir $decode_dir
If your KWS data directory has an extra ID, e.g., oov (this is useful when you have different KWS setups, in this case, your directory will look something like data/dev10h.uem/kws_oov), you have to run it with the extraid option:
local/kws_search.sh --cmd "$cmd" --extraid $extraid \
--max-states ${max_states} --min-lmwt ${min_lmwt} \
--max-lmwt ${max_lmwt} --skip-scoring $skip_scoring \
--indices-dir $decode_dir/kws_indices $lang_dir $data_dir $decode_dir
 1.8.13
1.8.13