 |
|
You will instantiate this class when you want to decode a single utterance using the online-decoding setup. More...
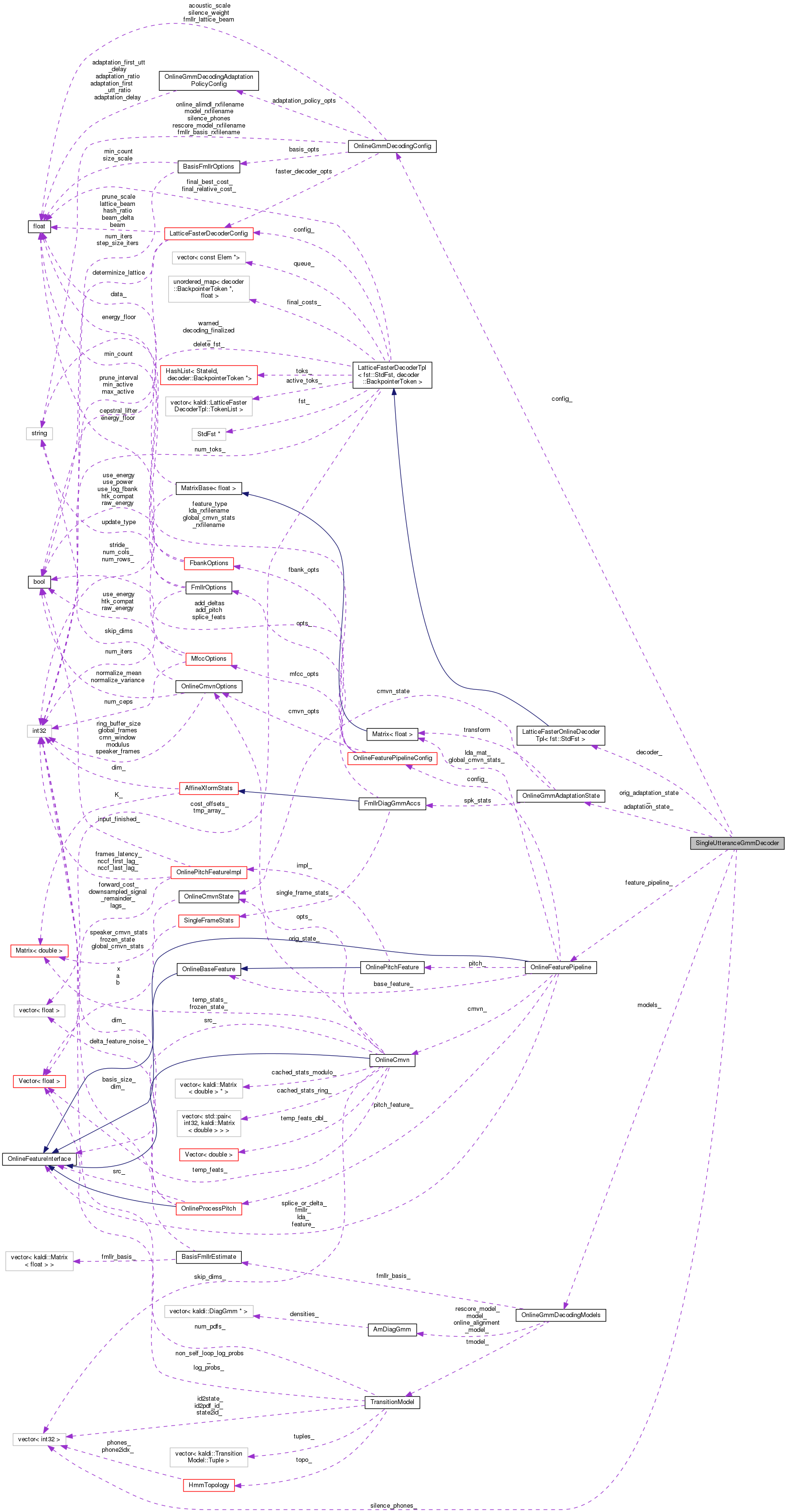
#include <online-gmm-decoding.h>
Public Member Functions | |
| SingleUtteranceGmmDecoder (const OnlineGmmDecodingConfig &config, const OnlineGmmDecodingModels &models, const OnlineFeaturePipeline &feature_prototype, const fst::Fst< fst::StdArc > &fst, const OnlineGmmAdaptationState &adaptation_state) | |
| OnlineFeaturePipeline & | FeaturePipeline () |
| void | AdvanceDecoding () |
| advance the decoding as far as we can. More... | |
| void | FinalizeDecoding () |
| Finalize the decoding. More... | |
| bool | HaveTransform () const |
| Returns true if we already have an fMLLR transform. More... | |
| void | EstimateFmllr (bool end_of_utterance) |
| Estimate the [basis-]fMLLR transform and apply it to the features. More... | |
| void | GetAdaptationState (OnlineGmmAdaptationState *adaptation_state) const |
| void | GetLattice (bool rescore_if_needed, bool end_of_utterance, CompactLattice *clat) const |
| Gets the lattice. More... | |
| void | GetBestPath (bool end_of_utterance, Lattice *best_path) const |
| Outputs an FST corresponding to the single best path through the current lattice. More... | |
| BaseFloat | FinalRelativeCost () |
| This function outputs to "final_relative_cost", if non-NULL, a number >= 0 that will be close to zero if the final-probs were close to the best probs active on the final frame. More... | |
| bool | EndpointDetected (const OnlineEndpointConfig &config) |
| This function calls EndpointDetected from online-endpoint.h, with the required arguments. More... | |
| ~SingleUtteranceGmmDecoder () | |
Private Member Functions | |
| bool | GetGaussianPosteriors (bool end_of_utterance, GaussPost *gpost) |
| bool | RescoringIsNeeded () const |
| Returns true if doing a lattice rescoring pass would have any point, i.e. More... | |
Private Attributes | |
| OnlineGmmDecodingConfig | config_ |
| std::vector< int32 > | silence_phones_ |
| const OnlineGmmDecodingModels & | models_ |
| OnlineFeaturePipeline * | feature_pipeline_ |
| const OnlineGmmAdaptationState & | orig_adaptation_state_ |
| OnlineGmmAdaptationState | adaptation_state_ |
| LatticeFasterOnlineDecoder | decoder_ |
You will instantiate this class when you want to decode a single utterance using the online-decoding setup.
This is an alternative to manually putting things together yourself.
Definition at line 216 of file online-gmm-decoding.h.
| SingleUtteranceGmmDecoder | ( | const OnlineGmmDecodingConfig & | config, |
| const OnlineGmmDecodingModels & | models, | ||
| const OnlineFeaturePipeline & | feature_prototype, | ||
| const fst::Fst< fst::StdArc > & | fst, | ||
| const OnlineGmmAdaptationState & | adaptation_state | ||
| ) |
Definition at line 48 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::adaptation_state_, SingleUtteranceGmmDecoder::config_, SingleUtteranceGmmDecoder::decoder_, SingleUtteranceGmmDecoder::feature_pipeline_, LatticeFasterDecoderTpl< FST, Token >::InitDecoding(), KALDI_ERR, OnlineFeaturePipeline::SetTransform(), OnlineGmmDecodingConfig::silence_phones, SingleUtteranceGmmDecoder::silence_phones_, kaldi::SortAndUniq(), kaldi::SplitStringToIntegers(), and OnlineGmmAdaptationState::transform.
Definition at line 305 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::feature_pipeline_.
| void AdvanceDecoding | ( | ) |
advance the decoding as far as we can.
May also estimate fMLLR after advancing the decoding, depending on the configuration values in config_.adaptation_policy_opts. [Note: we expect the user will also call EstimateFmllr() at utterance end, which should generally improve the quality of the estimated transforms, although we don't rely on this].
Definition at line 69 of file online-gmm-decoding.cc.
References OnlineGmmDecodingConfig::acoustic_scale, OnlineGmmDecodingConfig::adaptation_policy_opts, LatticeFasterDecoderTpl< FST, Token >::AdvanceDecoding(), SingleUtteranceGmmDecoder::config_, SingleUtteranceGmmDecoder::decoder_, OnlineGmmDecodingAdaptationPolicyConfig::DoAdapt(), SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::feature_pipeline_, OnlineFeaturePipeline::FrameShiftInSeconds(), OnlineGmmDecodingModels::GetModel(), OnlineGmmDecodingModels::GetOnlineAlignmentModel(), OnlineGmmDecodingModels::GetTransitionModel(), SingleUtteranceGmmDecoder::HaveTransform(), SingleUtteranceGmmDecoder::models_, LatticeFasterDecoderTpl< FST, Token >::NumFramesDecoded(), MatrixBase< Real >::NumRows(), SingleUtteranceGmmDecoder::orig_adaptation_state_, and OnlineGmmAdaptationState::transform.
| bool EndpointDetected | ( | const OnlineEndpointConfig & | config | ) |
This function calls EndpointDetected from online-endpoint.h, with the required arguments.
Definition at line 310 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::decoder_, kaldi::EndpointDetected(), SingleUtteranceGmmDecoder::feature_pipeline_, OnlineFeaturePipeline::FrameShiftInSeconds(), OnlineGmmDecodingModels::GetTransitionModel(), and SingleUtteranceGmmDecoder::models_.
| void EstimateFmllr | ( | bool | end_of_utterance | ) |
Estimate the [basis-]fMLLR transform and apply it to the features.
This will get used if you call RescoreLattice() or if you just continue decoding; however to get it applied retroactively you'd have to call RescoreLattice(). "end_of_utterance" just affects how we interpret the final-probs in the lattice. This should generally be true if you think you've reached the end of the grammar, and false otherwise.
Definition at line 208 of file online-gmm-decoding.cc.
References FmllrDiagGmmAccs::AccumulateFromPosteriors(), SingleUtteranceGmmDecoder::adaptation_state_, OnlineGmmDecodingConfig::basis_opts, AffineXformStats::beta_, BasisFmllrEstimate::ComputeTransform(), SingleUtteranceGmmDecoder::config_, SingleUtteranceGmmDecoder::decoder_, AffineXformStats::Dim(), VectorBase< Real >::Dim(), BasisFmllrEstimate::Dim(), OnlineFeaturePipeline::Dim(), SingleUtteranceGmmDecoder::feature_pipeline_, OnlineFeaturePipeline::FreezeCmvn(), OnlineFeaturePipeline::GetAsMatrix(), OnlineGmmDecodingModels::GetFmllrBasis(), OnlineFeaturePipeline::GetFrame(), SingleUtteranceGmmDecoder::GetGaussianPosteriors(), OnlineGmmDecodingModels::GetModel(), AmDiagGmm::GetPdf(), kaldi::GetVerboseLevel(), rnnlm::i, FmllrDiagGmmAccs::Init(), rnnlm::j, KALDI_ERR, KALDI_VLOG, KALDI_WARN, SingleUtteranceGmmDecoder::models_, LatticeFasterDecoderTpl< FST, Token >::NumFramesDecoded(), MatrixBase< Real >::NumRows(), SingleUtteranceGmmDecoder::orig_adaptation_state_, OnlineFeaturePipeline::SetTransform(), OnlineGmmAdaptationState::spk_stats, and OnlineGmmAdaptationState::transform.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding().
|
inline |
Definition at line 224 of file online-gmm-decoding.h.
| void FinalizeDecoding | ( | ) |
Finalize the decoding.
Cleanups and prunes remaining tokens, so the final result is faster to obtain.
Definition at line 105 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::decoder_, and LatticeFasterDecoderTpl< FST, Token >::FinalizeDecoding().
|
inline |
This function outputs to "final_relative_cost", if non-NULL, a number >= 0 that will be close to zero if the final-probs were close to the best probs active on the final frame.
(the output to final_relative_cost is based on the first-pass decoding). If it's close to zero (e.g. < 5, as a guess), it means you reached the end of the grammar with good probability, which can be taken as a good sign that the input was OK.
Definition at line 276 of file online-gmm-decoding.h.
References kaldi::EndpointDetected().
| void GetAdaptationState | ( | OnlineGmmAdaptationState * | adaptation_state | ) | const |
Definition at line 287 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::adaptation_state_, OnlineGmmAdaptationState::cmvn_state, SingleUtteranceGmmDecoder::feature_pipeline_, and OnlineFeaturePipeline::GetCmvnState().
Outputs an FST corresponding to the single best path through the current lattice.
If "use_final_probs" is true AND we reached the final-state of the graph then it will include those as final-probs, else it will treat all final-probs as one.
Definition at line 341 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::decoder_, and LatticeFasterOnlineDecoderTpl< FST >::GetBestPath().
Definition at line 111 of file online-gmm-decoding.cc.
References DiagGmm::ComponentPosteriors(), SingleUtteranceGmmDecoder::config_, kaldi::ConvertPosteriorToPdfs(), SingleUtteranceGmmDecoder::decoder_, fst::DeterminizeLatticePruned(), OnlineFeaturePipeline::Dim(), SingleUtteranceGmmDecoder::feature_pipeline_, OnlineGmmDecodingConfig::fmllr_lattice_beam, OnlineFeaturePipeline::GetFrame(), OnlineGmmDecodingModels::GetModel(), OnlineGmmDecodingModels::GetOnlineAlignmentModel(), AmDiagGmm::GetPdf(), LatticeFasterOnlineDecoderTpl< FST >::GetRawLatticePruned(), OnlineGmmDecodingModels::GetTransitionModel(), SingleUtteranceGmmDecoder::HaveTransform(), rnnlm::i, rnnlm::j, KALDI_ASSERT, KALDI_VLOG, KALDI_WARN, kaldi::LatticeForwardBackward(), SingleUtteranceGmmDecoder::models_, LatticeFasterDecoderTpl< FST, Token >::NumFramesDecoded(), kaldi::PruneLattice(), VectorBase< Real >::Scale(), SingleUtteranceGmmDecoder::silence_phones_, OnlineGmmDecodingConfig::silence_weight, kaldi::TopSortLatticeIfNeeded(), and kaldi::WeightSilencePost().
Referenced by SingleUtteranceGmmDecoder::EstimateFmllr().
| void GetLattice | ( | bool | rescore_if_needed, |
| bool | end_of_utterance, | ||
| CompactLattice * | clat | ||
| ) | const |
Gets the lattice.
If rescore_if_needed is true, and if there is any point in rescoring the state-level lattice (see RescoringIsNeeded()), it will rescore the lattice. The output lattice has any acoustic scaling in it (which will typically be desirable in an online-decoding context); if you want an un-scaled lattice, scale it using ScaleLattice() with the inverse of the acoustic weight. "end_of_utterance" will be true if you want the final-probs to be included.
Definition at line 318 of file online-gmm-decoding.cc.
References OnlineGmmDecodingConfig::acoustic_scale, SingleUtteranceGmmDecoder::config_, SingleUtteranceGmmDecoder::decoder_, LatticeFasterDecoderConfig::det_opts, fst::DeterminizeLatticePhonePrunedWrapper(), OnlineGmmDecodingConfig::faster_decoder_opts, SingleUtteranceGmmDecoder::feature_pipeline_, OnlineGmmDecodingModels::GetFinalModel(), LatticeFasterDecoderTpl< FST, Token >::GetRawLattice(), OnlineGmmDecodingModels::GetTransitionModel(), KALDI_WARN, LatticeFasterDecoderConfig::lattice_beam, SingleUtteranceGmmDecoder::models_, kaldi::PruneLattice(), kaldi::RescoreLattice(), and SingleUtteranceGmmDecoder::RescoringIsNeeded().
| bool HaveTransform | ( | ) | const |
Returns true if we already have an fMLLR transform.
The user will already know this; the call is for convenience.
Definition at line 283 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::feature_pipeline_, and OnlineFeaturePipeline::HaveFmllrTransform().
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), and SingleUtteranceGmmDecoder::GetGaussianPosteriors().
|
private |
Returns true if doing a lattice rescoring pass would have any point, i.e.
if we have estimated fMLLR during this utterance, or if we have a discriminative model that differs from the fMLLR model *and* we currently have fMLLR features.
Definition at line 293 of file online-gmm-decoding.cc.
References SingleUtteranceGmmDecoder::adaptation_state_, MatrixBase< Real >::ApproxEqual(), OnlineGmmDecodingModels::GetFinalModel(), OnlineGmmDecodingModels::GetModel(), SingleUtteranceGmmDecoder::models_, MatrixBase< Real >::NumRows(), SingleUtteranceGmmDecoder::orig_adaptation_state_, and OnlineGmmAdaptationState::transform.
Referenced by SingleUtteranceGmmDecoder::GetLattice().
|
private |
Definition at line 303 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::GetAdaptationState(), SingleUtteranceGmmDecoder::RescoringIsNeeded(), and SingleUtteranceGmmDecoder::SingleUtteranceGmmDecoder().
|
private |
Definition at line 293 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::GetGaussianPosteriors(), SingleUtteranceGmmDecoder::GetLattice(), and SingleUtteranceGmmDecoder::SingleUtteranceGmmDecoder().
|
private |
Definition at line 304 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), SingleUtteranceGmmDecoder::EndpointDetected(), SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::FinalizeDecoding(), SingleUtteranceGmmDecoder::GetBestPath(), SingleUtteranceGmmDecoder::GetGaussianPosteriors(), SingleUtteranceGmmDecoder::GetLattice(), and SingleUtteranceGmmDecoder::SingleUtteranceGmmDecoder().
|
private |
Definition at line 297 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), SingleUtteranceGmmDecoder::EndpointDetected(), SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::GetAdaptationState(), SingleUtteranceGmmDecoder::GetGaussianPosteriors(), SingleUtteranceGmmDecoder::GetLattice(), SingleUtteranceGmmDecoder::HaveTransform(), SingleUtteranceGmmDecoder::SingleUtteranceGmmDecoder(), and SingleUtteranceGmmDecoder::~SingleUtteranceGmmDecoder().
|
private |
Definition at line 296 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), SingleUtteranceGmmDecoder::EndpointDetected(), SingleUtteranceGmmDecoder::EstimateFmllr(), SingleUtteranceGmmDecoder::GetGaussianPosteriors(), SingleUtteranceGmmDecoder::GetLattice(), and SingleUtteranceGmmDecoder::RescoringIsNeeded().
|
private |
Definition at line 298 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::AdvanceDecoding(), SingleUtteranceGmmDecoder::EstimateFmllr(), and SingleUtteranceGmmDecoder::RescoringIsNeeded().
|
private |
Definition at line 294 of file online-gmm-decoding.h.
Referenced by SingleUtteranceGmmDecoder::GetGaussianPosteriors(), and SingleUtteranceGmmDecoder::SingleUtteranceGmmDecoder().
 1.8.13
1.8.13