 |
|
In the Kaldi toolkit there is no single "canonical" decoder, or a fixed interface that decoders must satisfy.
There are currently two decoders available: SimpleDecoder and FasterDecoder; and there are also lattice-generating versions of these (see Lattice generating decoders). By "decoder" we mean the internal code of the decoder; there are command-line programs that wrap these decoders so that they can decode particular types of model (e.g. GMMs), or with particular special conditions (e.g. multi-class fMLLR). Examples of command-line programs that decode are gmm-decode-simple, gmm-decode-faster, gmm-decode-kaldi, and gmm-decode-faster-fmllr. We have avoided creating a single command-line program that can do every possible kind of decoding, as this could quickly become hard to modify and debug.
In order to minimize the interaction between the decoder and the acoustic modeling code, we have created a base class (DecodableInterface) which mediates between the decoder and the acoustic modeling code. The DecodableInterface object can be viewed as a wrapper for the pair (acoustic model, feature file). This might seem a slightly unnatural object. However, there is a good reason for its existence. The interaction between the acoustic model and the features can be quite complex (think about adaptation with multiple transforms), and by taking this out of the decoder we substantially simplify what the decoder has to know. The DecodableInterface object can be thought of as a matrix of size (number of frames) by (number of nonzero input labels on the graph).
The basic operation of a decoder is to "decode this object of type DecodableInterface".
The DecodableInterface object has only three functions:
virtual BaseFloat LogLikelihood(int32 frame, int32 index); virtual int32 NumFramesReady() const; virtual bool IsLastFrame(int32 frame); virtual int32 NumIndices();
The function LogLikelihood() returns the log-likelihood for this frame and index; the index would normally be the (one-based) transition-id, see Integer identifiers used by TransitionModel. The frame is a zero-based quantity. The most normal DecodableInterface object will just look up the appropriate feature vector (using the index "frame"), work out the pdf-id corresponding to that transition-id, and return the corresponding acoustic log-likelihood. Acoustic probability scales are also applied by the DecodableInterface object, but they are not part of its generic interface because the interface represents the minimum that the decoder "needs to know", and it does not need to know about the probability scales.
The NumFramesReady() function returns the number of frames currently available. In an offline, batch-mode setting this will equal the number of frames in the file. In an online setting this will be the number of frames we have already captured and processed into features, and it will likely increase with time. The IsLastFrame() function is an older mechanism for online decoding; it returns true if the given frame is the last one (in the old online-decoding mechanism, which is still supported for back compatibility, the call to the IsLastFrame() function would block if it was not the last frame but the data was not yet available.
As an illustration of a "prototypical" decoder, consider the class SimpleDecoder. This very simple decoder has been included mostly for reference and for debugging more highly optimized decoders.
The constructor of SimpleDecoder takes the FST to decode with, and a decoding beam:
SimpleDecoder(const fst::Fst<fst::StdArc> &fst, BaseFloat beam);
Decoding an utterance is accomplished by the following function:
void Decode(DecodableInterface &decodable);
Here is an example code fragment where we construct a Decodable object and decode it:
DecodableAmDiagGmmScaled gmm_decodable(am_gmm, trans_model, features,
acoustic_scale);
decoder.Decode(gmm_decodable);
The type DecodableAmDiagGmmScaled is a very simple object that, given a transition-id, works out from trans_model (type: TransitionModel) the appropriate pdf-id, gets the corresponding row from the features (type: Matrix<BaseFloat>), works out the likelihood from am_gmm (type: AmDiagGmm), and scales it by acoustic_scale (type: float).
After calling this, we can get the traceback with the following call:
bool GetBestPath(Lattice *fst_out);
The output is formatted as a lattice but contains only one path. The lattice is a finite-state transducer whose input and output labels are whatever labels were on the FST (typically transition-ids and words, respectively), and whose weights contain the acoustic, language model and transition weights.
This decoder stores tracebacks at the token level that are garbage collected. The token is of type SimpleDecoder::Token, which has the following member variables:
class Token {
public:
Arc arc_;
Token *prev_;
int32 ref_count_;
Weight weight_;
...
The member of type Arc (this is a typedef to fst::StdArc) is a copy of the arc in the original FST, except it has the acoustic likelihood contribution added in. It contains the input and output labels, the weight and the next state (in the FST). The "prev_" member is the traceback; the "ref_count_" is used in the garbage collection algorithm; the "Weight" is a typedef to fst::StdArc::Weight but essentially it just stores a floating-point value which represents the accumulated cost up to this point.
Class SimpleDecoder contains just four data members, declared as follows:
unordered_map<StateId, Token*> cur_toks_; unordered_map<StateId, Token*> prev_toks_; const fst::Fst<fst::StdArc> &fst_; BaseFloat beam_;
The last two of these (the FST and the beam) are constant during decoding. The members "cur_toks_" and "prev_toks_" store the currently active tokens for the current and previous frame respectively. The central loop of the Decode() function is as follows:
for(int32 frame = 0; !decodable.IsLastFrame(frame-1); frame++) {
ClearToks(prev_toks_);
std::swap(cur_toks_, prev_toks_);
ProcessEmitting(decodable, frame);
ProcessNonemitting();
PruneToks(cur_toks_, beam_);
}
These statements are all self-explanatory except for ProcessEmitting() and ProcessNonemitting(). The ProcessEmitting() function propagates tokens from prev_toks_ (i.e. the previous frame) to cur_toks_ (i.e. the current frame). It only considers emitting arcs (i.e. arcs with nonzero input label). For each token (say "tok") in prev_toks_, it looks at the state associated with the token (in tok->arc_.nextstate), and for each arc out of that state that is emitting, it creates a new token with a traceback to "tok" and with an "arc_" field coped from that arc, except with the associated weight updated to include the acoustic contribution. The "weight_" field, representing the accumulated cost up to this point, will be the sum (the product, in the semiring interpretation) of tok->weight_ and the weight of the recently added arc. Each time we attempt to add a new token to "cur_toks_", we have to make sure there is no existing token associated with the same FST state. If there is, we keep only the best.
The function ProcessNonemitting() deals only with cur_toks_ and not with prev_toks_; it propagates nonemitting arcs, i.e. arcs with zero/<eps> as the input label/symbol. The newly created tokens will point back to other tokens in cur_toks_. The weights on the arcs will just be the weights from the FST. ProcessNonemitting() may have to process chains of epsilons. It uses a queue to store states that need to be processed.
After decoding, the function GetOutput(), discussed above, will trace back from the most likely token at the final state (taking into account its final probability, if is_final==true), and produce a linear FST with one arc for each arc in the traceback sequence. There may be more of these than the number of frames, since there are separate tokens created for nonemitting arcs.
The decoder FasterDecoder has almost exactly the same interface as SimpleDecoder. The only important new configuration value is "max-active", which controls the maximum number of states that can be active at one time. Apart from enforcing the max-active states, the only major difference is a data-structure related one. We replace the type std::unordered_map<StateId, Token*> with a new type HashList<StateId, Token*>, where HashList is our own templated type created for this purpose. HashList stores a singly-linked-list structure whose elements are also accessible via a hash table, and it offers the capability to free up the hash table for a new list structure while giving sequential access to the old list structure. This is so that we can use the hash table to access what in SimpleDecoder was cur_toks_, while still having access to what in SimpleDecoder was prev_toks_, in the form of a list.
The main pruning step FasterDecoder takes place in ProcessEmitting. Conceptually what is happening is that we take the tokens in what in SimpleDecoder was prev_toks_, and just before ProcessEmitting we prune using the beam and specified maximum number of active states (whichever is tighter). The way this is actually implemented is that we call a function GetCutoff(), which returns a weight cutoff value "weight_cutoff" that corresponds to the tighter of these two criteria; this cutoff value applies to the tokens in prev_toks_. Then when we go through prev_toks_ (this variable does not exist in FasterDecoder, but conceptually), we only process those tokens better than the cutoff.
The code in FasterDecoder as it relates to cutoffs is a little more complicated than just having the one pruning step. The basic observation is this: it's pointless to create a very large number of tokens if you are only going to ignore most of them later. So the situation in ProcessEmitting is: we have "weight_cutoff" but wouldn't it be nice if we knew what the value of "weight_cutoff" on the next frame was going to be? Call this "next_weight_cutoff". Then, whenever we process arcs that have the current frame's acoustic likelihoods, we could just avoid creating the token if the likelihood is worse than "next_weight_cutoff". In order to know the next weight cutoff we have to know two things. We have to know the best token's weight on the next frame, and we have to know the effective beam width on the next frame. The effective beam width may differ from "beam" if the "max_active" constraint is limiting, and we use the heuristic that the effective beam width does not change very much from frame to frame. We attempt to estimate the best token's weight on the next frame by propagating the currently best token (later on, if we find even better tokens on the next frame we will update this estimate). We get a rough upper bound on the effective beam width on the next frame by using the variable "adaptive_beam". This is always set to the smaller of "beam" (the specified maximum beam width), or the effective beam width as determined by max_active, plus beam_delta (default value: 0.5). When we say it is a "rough upper bound" we mean that it will usually be greater than or equal to the effective beam width on the next frame. The pruning value we use when creating new tokens equals our current estimate of the next frame's best token, plus "adaptive_beam". With finite "beam_delta", it is possible for the pruning to be stricter than dictated by the "beam" and "max_active" parameters alone, although at the value 0.5 we do not believe this happens very often.
There are two basic ways in Kaldi to use large language models (i.e. language models larger than a few million arcs, for which it would be difficult to successfully build the decoding graph). One way is to generate a lattice using a small LM, and to rescore this lattice with a large LM (see Lattice generating decoders below, and also Lattices in Kaldi). The other way is to use a "biglm" decoder, e.g. BiglmFasterDecoder. The basic idea is to create the decoding graph HCLG with a small grammar, and compose dynamically with the difference between a large grammar and the small grammar. Note that while we use the word "grammar" for compatibility with the standard notation, we have in mind a statistical language model. Imagine that the small grammar is G (an FST), and the large one is G'. The basic idea is to search, in decoding time, the graph formed by the triple composition 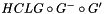 , where
, where 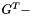 is like
is like 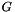 but with its scores negated. We'll give the high-level idea of how we do this first. We construct an on-demand composed FST, call it F, which is
but with its scores negated. We'll give the high-level idea of how we do this first. We construct an on-demand composed FST, call it F, which is 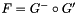 . Then while decoding, we construct on-demand the FST
. Then while decoding, we construct on-demand the FST 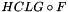 . The problem with this is that we would always take the worst-scoring path through G, e.g. improperly take the backoff arc, which would make the subtraction of the original FST scores incorrect.
. The problem with this is that we would always take the worst-scoring path through G, e.g. improperly take the backoff arc, which would make the subtraction of the original FST scores incorrect.
The way we solve the problem above is to use some knowledge about the structure of $G$ and $G'$ (we assume they are are ARPA-style language models), and treat them as epsilon-free, deterministic FSTs. That is: when searching for an arc from a particular state with a particular input label, if we find that input label we take it (and return just that arc), otherwise we follow the epsilon transition, and recursively look for an arc with that label. In terms of the external interface of the FST, it looks like there was an arc from the original state (i.e. it looks like a language model FST that has been subjected to epsilon removal). We created a special interface for this type of FST, which we call fst::DeterministicOnDemandFst; it has a new function GetArc(), which finds the arc with a particular input label, if it exists (by assumption, there cannot be more than one). Both G and G' are of type fst::DeterministicOnDemandFst, and so is their composition. This means that the decoder doesn't have to implement a generic composition algorithm; instead, whenever it crosses an arc in HCLG, it has only to update the language-model state (a state-identifier in F). The decoding algorithm is almost exactly the same as for the baseline, except the state-space (a hash index that we use) is not just the state in HCLG, but a pair of (state in HCLG, state in F). There is no subtantial extra work introduced by this, but this decoder is still a bit slower (e.g. nearly twice as slow in a typical setup) versus a decoder with the same beam, without the "biglm" part. The reason seems to be that with the biglm decoder, more states are in the beam (because a state in HCLG may now have more ``copies'', corresponding to different different histories with distinct langauage model states in HCLG. However, with the same beam, the biglm decoder does give better accuracy than lattice rescoring of lattices produced with a small grammar. The reason, we believe, is better pruning: the ``biglm'' decoder does the Viterbi beam pruning with closer-to-optimal language model scores. Of course, it is still not as good pruning as we would get by using a HCLG compiled with the big grammar, because the biglm decoder only updates the ``good'' language model score every time it crosses a word.
There are lattice-generating versions of some of the decoders described above. There is LatticeFasterDecoder, LatticeSimpleDecoder, and LatticeBiglmFasterDecoder. See Lattices in Kaldi for more details on lattice generation.
 1.8.13
1.8.13